We're All Script Kiddies 1 - Domains for Evil
Quickly grabbing domains for phishing or other purposes with as little effort as possible.
09 Jun 2017 - David E. Switzer
Intro
Preface: This was a talk I gave at BSides: Orlando 2017. Initially I thought this would fill out a good 30 minutes, but ended up being closer to 10 or 15. Oops. If you’d like to see me walk around and talk about it, the video is available at BSides:Orlando’s Youtube channel.
My day job is being part of a red team. Yes, hacking for a living. Cue the stock photos of hoodie-laden people in a dark room, wearing gloves and typing away. gloves and typing away.

Our track record is at 100%. Just like saying “I hack people for a living”, that statement conjures up an exciting, awesome vision that’s a bit different than reality. The boring truth is… it’s all about phishing. With enough research, phishing gets you in every time.
In the end, we’re all script kiddies.
Phishing and Evil Domains
It’s safe to assume if you’re reading this article, you’ve probably done some phishing. The first few times it works, it’s exciting. After a while it becomes a bit of a bore. The initial access is awesome, but a lot of the setup and prep is tedious.
This idea/blog/talk started from a discussion I had with a lead analyst at my day job (Hi Casey!). The discussion was about how to detect evil domains.
His proposed idea of detecting evil domains was:
- TLD - “.com” and “.net” were thought to host less evil than a “.at” domain.
- Age - Was this domain created last week, or has it been around a while?
- Categorization - What do various web-proxy/scanning companies say the site is? Ex: Bluecoat, etc.
I didn’t agree with the TLD portion, and yes, we know about domain fronting, but that’s not what this blog/talk was about :).
Testing the Theory
I was curious about the theory. I randomly picked a domain I’d bought for an engagement/client.
- TLD check: It’s a “.com”.
- Age check: Six months old, it’s good!
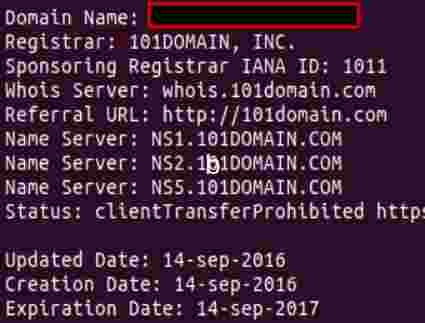
- Categorization check:
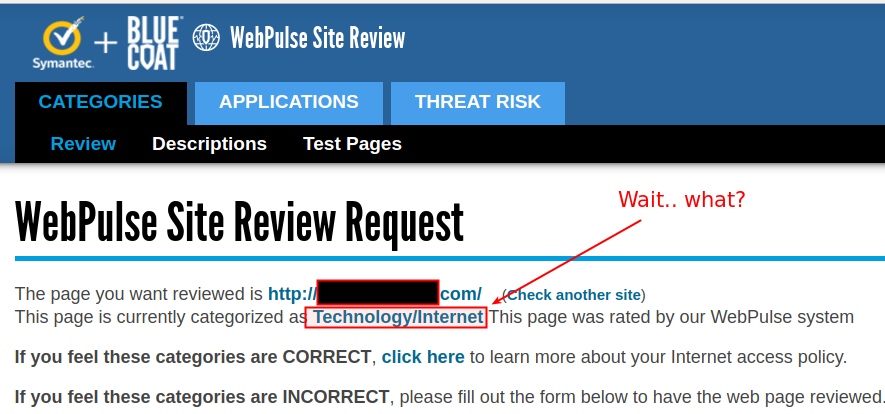
.. Huh? How is this categorized, I’ve never used nor setup this domain?

While I’d never used this domain, it turns out that Bluecoat had crawled the “website”, and the parked-page from 101Domains was keyword-y enough to qualify it as “Technology/Internet”. Neat!
So, let’s review. This domain I’ve never used meets all three categories: It’s a “trustworthy” TLD, it’s not brand new, and it’s been categorized. We’re golden!
So what, it’s a parked domain?
I get it. While this has been an amusing analysis of a domain I bought a while back, who cares? Anyone who looked at this page would see it’s a parked page, and obviously suspect. This feels like over-analysis of a corner case example.
My thought was… how can we do this in a more believable way, that’s the least “labor” intensive?
Domain Aging or go Vintage ?
In many ways, buying the domains yourself and let them “age” is the preferable route.
But that takes planning ahead, and time. Sometimes that just isn’t possible, so screw it. Let’s go vintage!

Finding Expired Domains
Manually searching for expired domains seemed like a lot of work, so let’s avoid that. Enter “ExpiredDomains”
Sign up for an account – it’s free and provides better search options.
Results show you the “birth dates”, 12 month Google search averages, and when the domain was dropped.
A Personal Internet Rule
“Wait long enough, and someone will code it for you.”
While digging through domains, I thought “OK, maybe I should just code something to do this for me”, and my personal internet rule hit. I ran across DomainHunter by Joe Vest (@joevest) and Andrew Chiles (@andrewchiles).
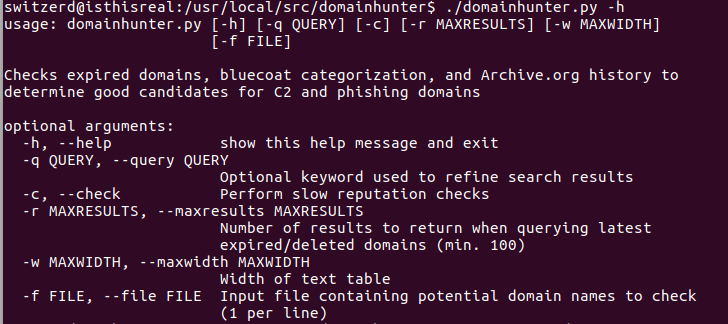
It automates finding a domain based on keyword, and even checks it against Bluecoat and IBM XForce to see if the domain is categorized. Awesome!
Keeping It Orlando
As this was a talk at BSides: Orlando, I decided to keep it Orlando themed, and searched for any related domains.
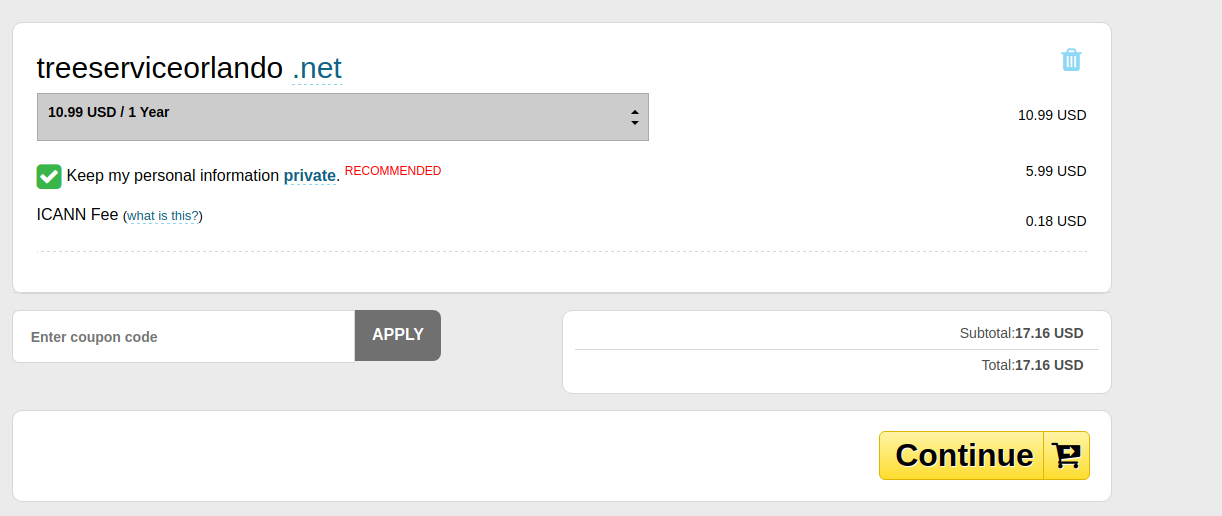
Perfect. I now have a domain. But it’d yet again be a parked page, which would alert anyone who looked at it that it was likely a “bad domain”. So how can we add some content to this, without much effort?
Wayback Machine To The Rescue
Why make content when someone has already done that for you?
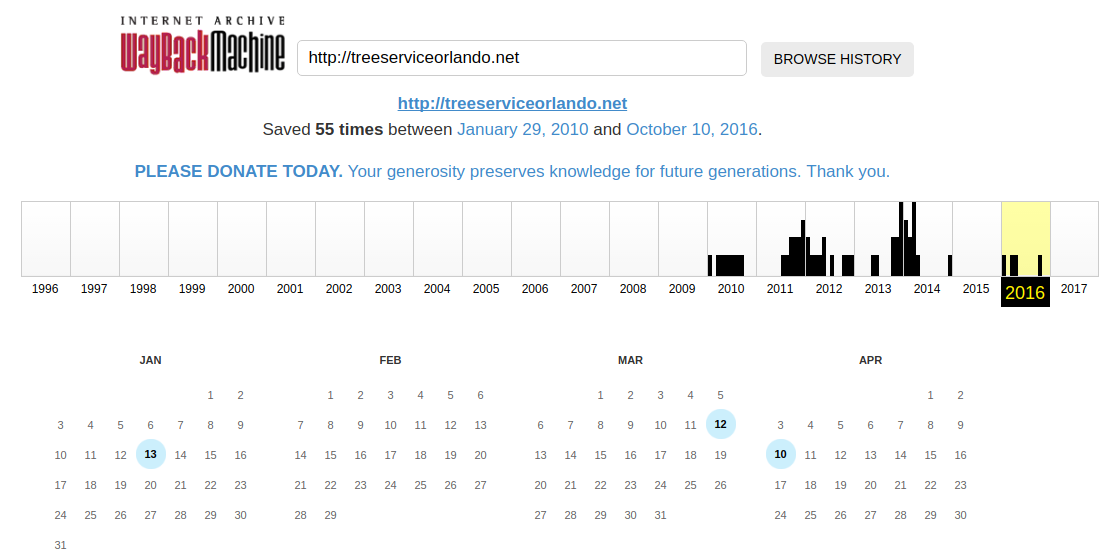
Perfect!
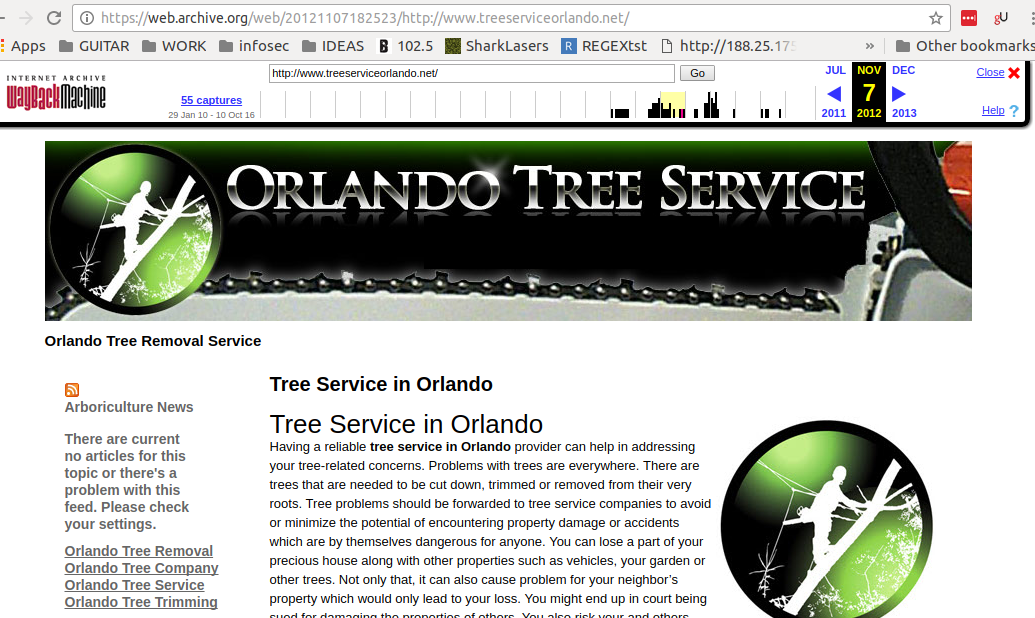
A tip for stealing content from the Wayback Machine.
If you want this url: https://web.archive.org/web/20121107182523/http://www.treeserviceorlando.net but without the WebArchive toolbar?
Add “id_” before the referenced url: https://web.archive.org/web/20121107182523id_/http://www.treeserviceorlando.net
Please note: The Wayback Machine doesn’t download jpgs or stylesheets when you add the “id_” to the url. Simply wget the regular version (with the toolbar, jpgs and style sheets), then wget the “id_” version later. It will write over the htmls w/ versions that don’t include the toolbar, and leave the rest in place.
We set up the DNS records, uploaded the content, and now we have a website:
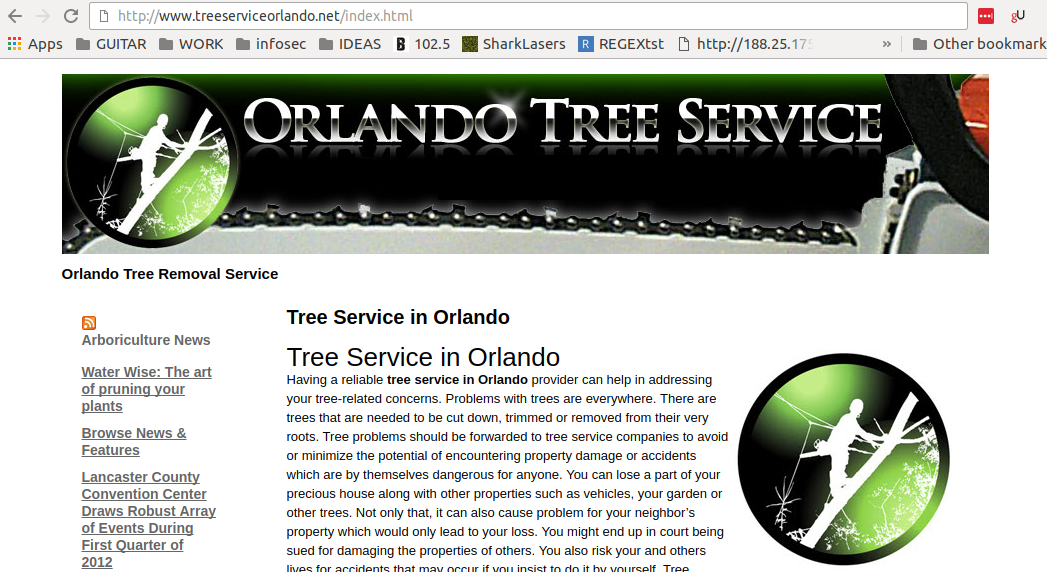
So, what can we do to make this even more legitimate looking?
“Let’s Encrypt” .. Sure, Why Not?
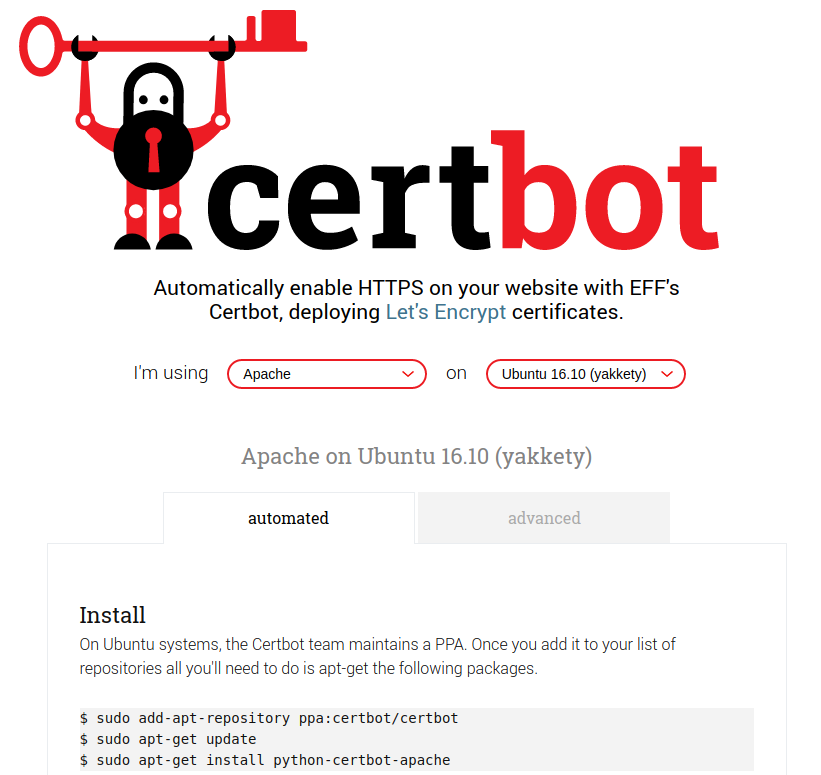
Let’s Encrypt makes it insanely easy. They even provide Linux distribution specific configuration tools. “certbot –apache”, hit enter a few times, and you’re left with your newly encrypted website! It even sets up your Apache configs!
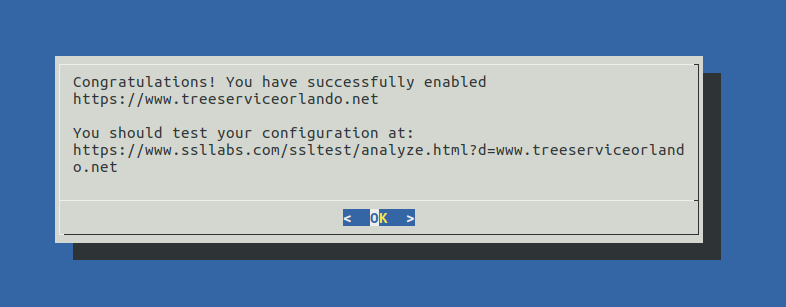
Neato, we’re secure!
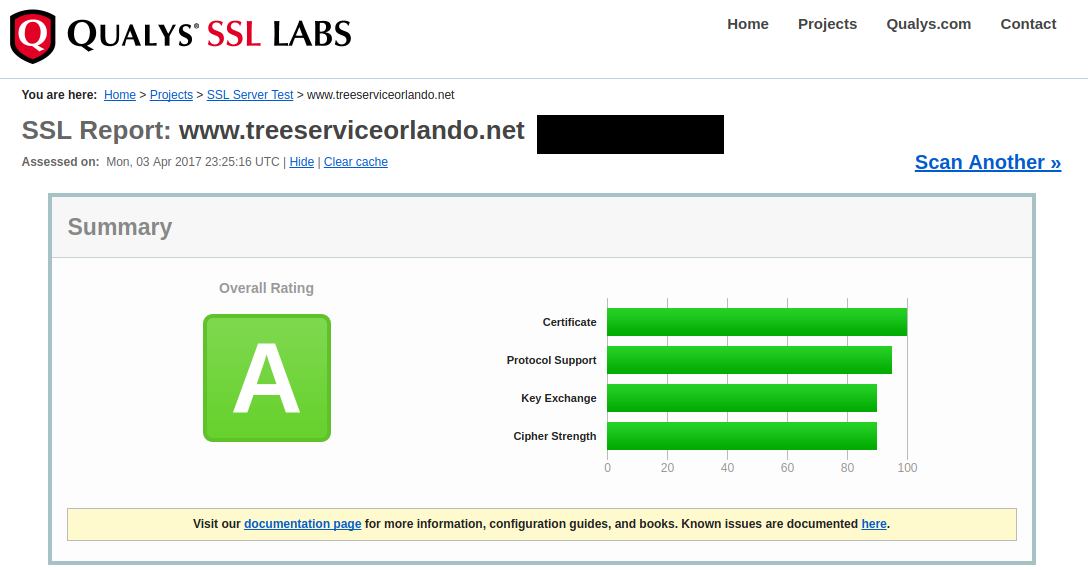
Let’s Review
- Categorization - Yep! Bluecoat thinks it is a vehicle related site.
- TLD - Yep! A shiny, trust worthy dot net!
- BONUS ENCRYPTION CERT - Totally trustworthy.
- Age ..
Typing “domain age history” into Google, and hitting “I Feel Lucky” turned up a service from WebConfs that lets you see the age of domains.
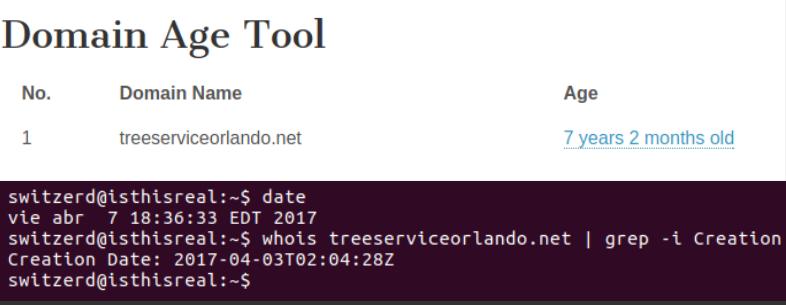
Obviously these sorts of tools (age checker, or Bluecoat, or..) don’t check every single domain every day, so you have a fantastic chance of having old data around. This site things the domain is over 7 years old.
So now we’re left with a domain that cost $17.16, can be hosted on a cheap or free hosting service, has legitimate content and some service thinks it is 7 years old. And this was all done in about a half hour.
Sometimes playing the scriptkiddie works out.